
DeepSeek发布了新一代开源大模型DeepSeek-R1。该模型在数学、代码、自然语言推理等任务上的性能与美国OpenAI公司的最新o1大模型相当。根据数据,DeepSeek-R1在算法类代码场景(Codeforces)和知识类测试(GPQA、MMLU)中的得分略低于OpenAI o1,但在工程类代码场景(SWE-Bench Verified)、美国数学竞赛(AIME 2024, MATH)项目上表现更优。
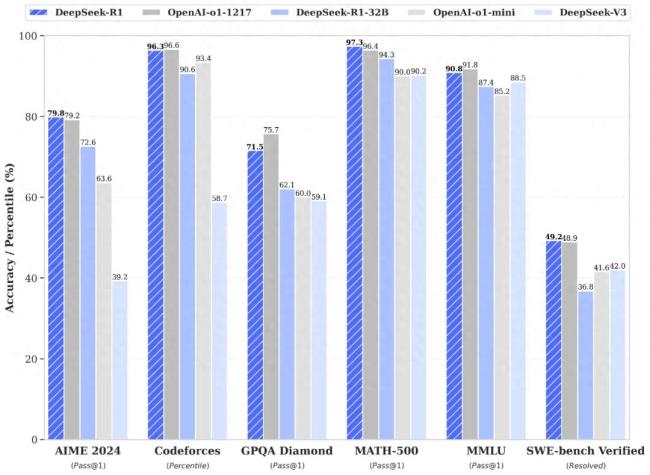

与之前发布的DeepSeek-V3相比,DeepSeek-R1在AIME 2024和Codeforces中的得分提升了近一倍,其他方面也有所提升。深度求索更新了用户协议,明确模型开源许可将使用标准的MIT许可,并允许用户利用模型输出训练其他模型。数据显示,在基于DeepSeek-R1进行“蒸馏”的6个小模型中,32B和70B模型在多项能力上对标了OpenAI的o1-mini。
深度求索表示,DeepSeek-R1后训练阶段大量使用了强化学习技术,在极少人工标注数据的情况下显著提升了模型推理能力,几乎跳过了监督微调步骤。这使得DeepSeek-R1能够自我优化,生成更符合人类偏好的内容。尽管强化学习需要大量反馈且计算成本高,但其优势在于不依赖高质量的人工标注数据。

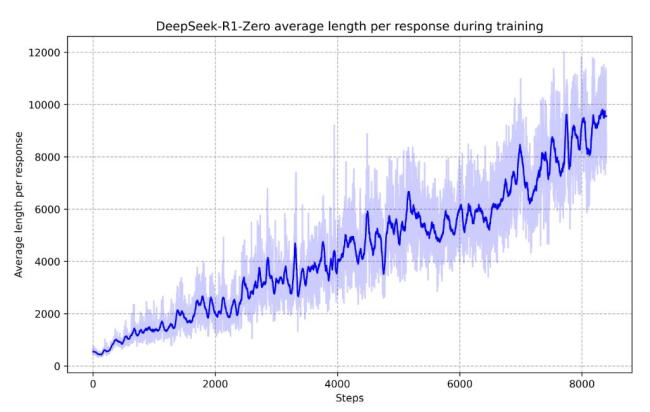
值得注意的是,深度求索还开发了一个完全通过大规模强化学习替代监督微调的大模型DeepSeek-R1-Zero,但因存在一些问题未对外公开。工作人员发现,在自我学习过程中,DeepSeek-R1-Zero出现了复杂行为,如自我反思、评估先前步骤、自发寻找替代方案的情况,甚至有一次“尤里卡时刻”。这种现象表明模型学会了用拟人化的语气进行自我反思,并主动为问题分配更多时间重新思考。
尽管DeepSeek-R1-Zero展示出强大的推理能力,但也出现了一些语言混乱及可读性问题。为此,深度求索引入数千条高质量冷启动数据和多段强化学习来解决这些问题,最终推出了正式版的DeepSeek-R1。目前,DeepSeek-R1 API服务定价为每百万输入tokens 1元(缓存命中)/4元(缓存未命中),每百万输出tokens 16元。
文章来源于网络。发布者:火星财经,转载请注明出处:https://www.sengcheng.com/article/7147.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 