
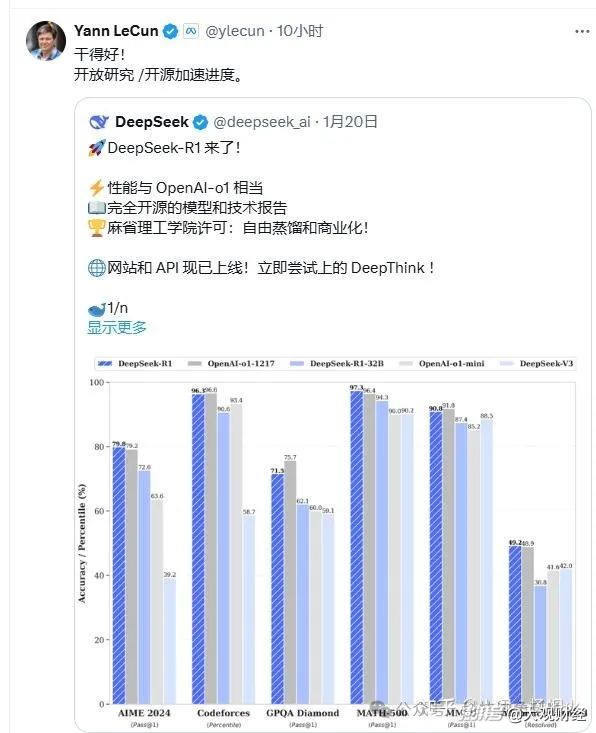
中国大模型技术和产业链的发展速度显著,Deepseek和阿里巴巴在开源方面已经领先Meta,成为全球开源领域的佼佼者。目前,国内发布的推理模型效果基本与o1持平,尽管仍弱于o3,但技术路线已经走通,追上甚至赶超只是时间问题。


DeepSeek的崛起为中国掌握下一代行业标准提供了机会,甚至可能使美国的芯片禁令变得无效。关于DeepSeek是否能改变全球AI竞争格局的问题,AGI短期内不会实现,至少十年内不会有全知全能的模型出现。因此,各行业仍然需要根据具体需求定制多种模型。训练模型的主要成本在于预训练阶段,而后续训练阶段的成本相对较低。
传统SFT阶段,模型只能从标注样本中学习知识,效果一般且容易过拟合。DeepSeek V3开创了一种新范式:资金雄厚且具有理想主义色彩的公司可以训练更大更好的模型并开源。各行业利用这些模型蒸馏出专用模型,再进行微调或直接调用API。这样,整个行业形成了一条分工协作的产业链,上下游企业各司其职,发挥各自的优势。
算力瓶颈问题也可以通过这种方式解决,因为只有大模型预训练阶段最消耗算力,即使通过非常规手段也能应对。DeepSeek关联公司杭州深度求索人工智能基础技术研究有限公司注册资本1000万元,法定代表人裴湉,由宁波程恩企业管理咨询合伙企业持股99%,梁文锋持股1%。
DeepSeek不仅完全开源,还放出了详细的技术报告,并开源了最大671B R1模型及多个尺寸的蒸馏模型,采用宽松的MIT License协议,允许任何人免费使用、修改、分发,包括商业用途。这种开放性使其受到广泛支持,被誉为真正的OpenAI。
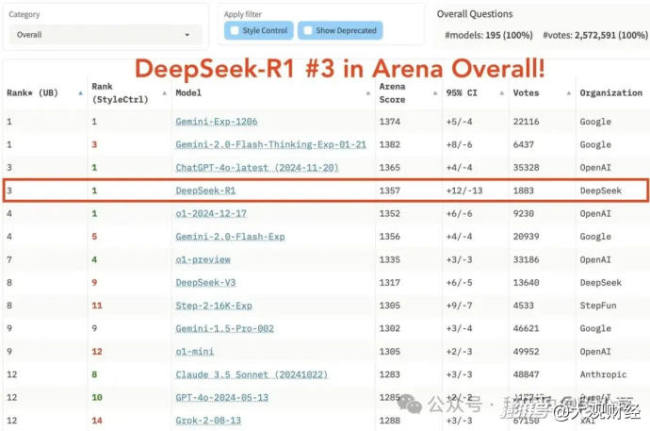
DeepSeek的训练成本也出乎意料地低,总训练成本仅为557.6万美元。这使得其在大模型市场上的逻辑发生了根本变化,过去认为非常烧钱的事情现在变得不再那么昂贵。此外,DeepSeek模型性能强大,在某些评测中甚至超越了GPT-4o和o1。考虑到其免费使用和低廉的API价格,综合用户成本来看,体验达到T1级别。
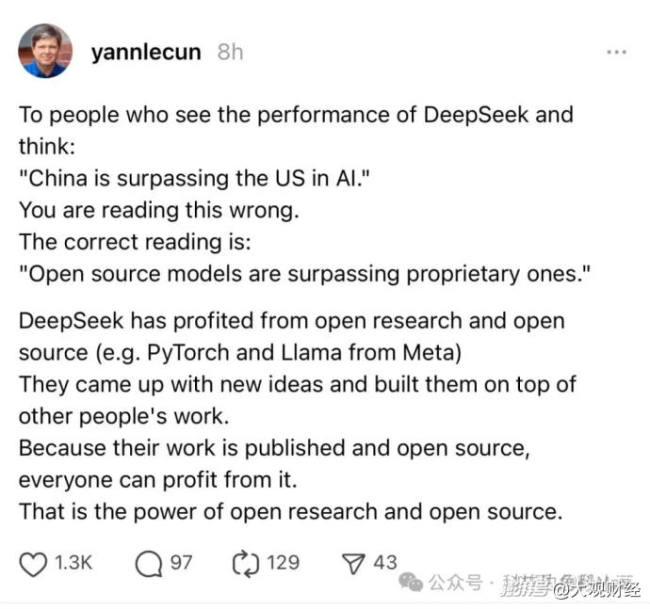
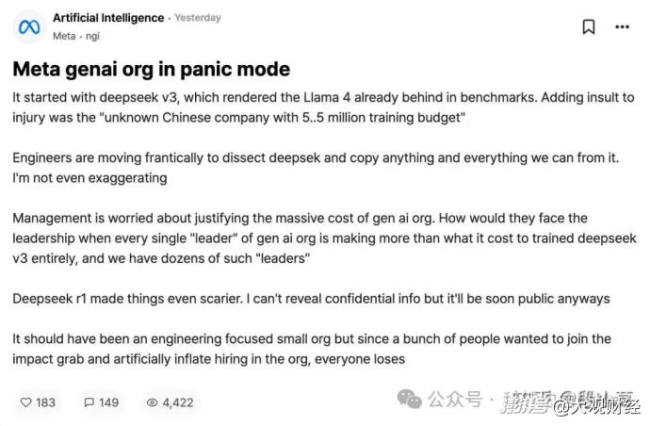
DeepSeek来自幻方量化而非传统互联网大厂,更具理想主义气息。创始人梁文锋近期备受关注,他的言论被逐字解读,增加了讨论热度。相比之下,DeepSeek商业气息较少,更像是一个小而美的研究机构。
美国明确表示要挑起AI竞赛,特朗普宣布5000亿美元投资星际之门计划,意图遏制中国AI发展。在这种背景下,中国企业推出DeepSeek,对国内来说是振奋人心的消息。DeepSeek不仅降低了训练成本,还在一定程度上削弱了对高性能显卡的依赖,这对美国来说难以接受。未来,全世界的工程师可能会从Qwen和DeepSeek开始学习大模型,或许这将是中国公司首次掌握互联网基建标准的机会。
文章来源于网络。发布者:火星财经,转载请注明出处:https://www.sengcheng.com/article/14848.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 