
9月29日,深度求索(DeepSeek)正式推出实验性版本DeepSeek-V3.2-Exp。这款被业内视为“新一代架构过渡之作”的模型,不仅引入了全新的稀疏注意力机制,更将API调用成本直接砍半——这是要彻底打破大模型“算力军备竞赛”的魔咒吗?


稀疏注意力首秀 长文本处理效率跃升
作为V3.1-Terminus的迭代版本,V3.2-Exp最核心的突破在于引入DeepSeek Sparse Attention(DSA)稀疏注意力机制。不同于传统Transformer架构中“全量计算”的模式,DSA通过细粒度稀疏化注意力矩阵,在处理长文本时将计算量从“平方级增长”压缩至“线性可控”。官方测试显示,在保持与V3.1-Terminus性能基本持平的前提下,模型训练和推理效率实现显著提升。

具体来看,在数学推理领域,AIME2025评测分数从88.4提升至89.3;编程能力方面,Codeforces竞赛评级从2046分跃升至2121分,相当于从“专业级”向“专家级”迈进。更关键的是,这种提升并非依赖参数规模扩张——该模型总参数量仍为671B,激活参数37B,却实现了160K长序列上下文的高效处理,这意味着能一次性“消化”30万字文档或超长篇代码库。
“传统注意力机制处理10万字文本时,计算量会飙升至1万亿次,而DSA能将其控制在2000亿次以内。”DeepSeek技术团队在论文中解释,这种优化源于对注意力矩阵的“动态剪枝”,仅保留关键关联权重,从而在精度损失小于1%的情况下,将硬件资源占用降低40%。
API成本腰斩 华为云适配加速商业化落地
伴随技术突破的,是极具冲击力的商业举措。DeepSeek宣布,V3.2-Exp API调用成本降低50%以上,新价格即刻生效。以“未命中缓存输入”为例,原单价从2元/百万tokens降至1元,输出价格从8元/百万tokens降至4元,直接对标行业最低水平。
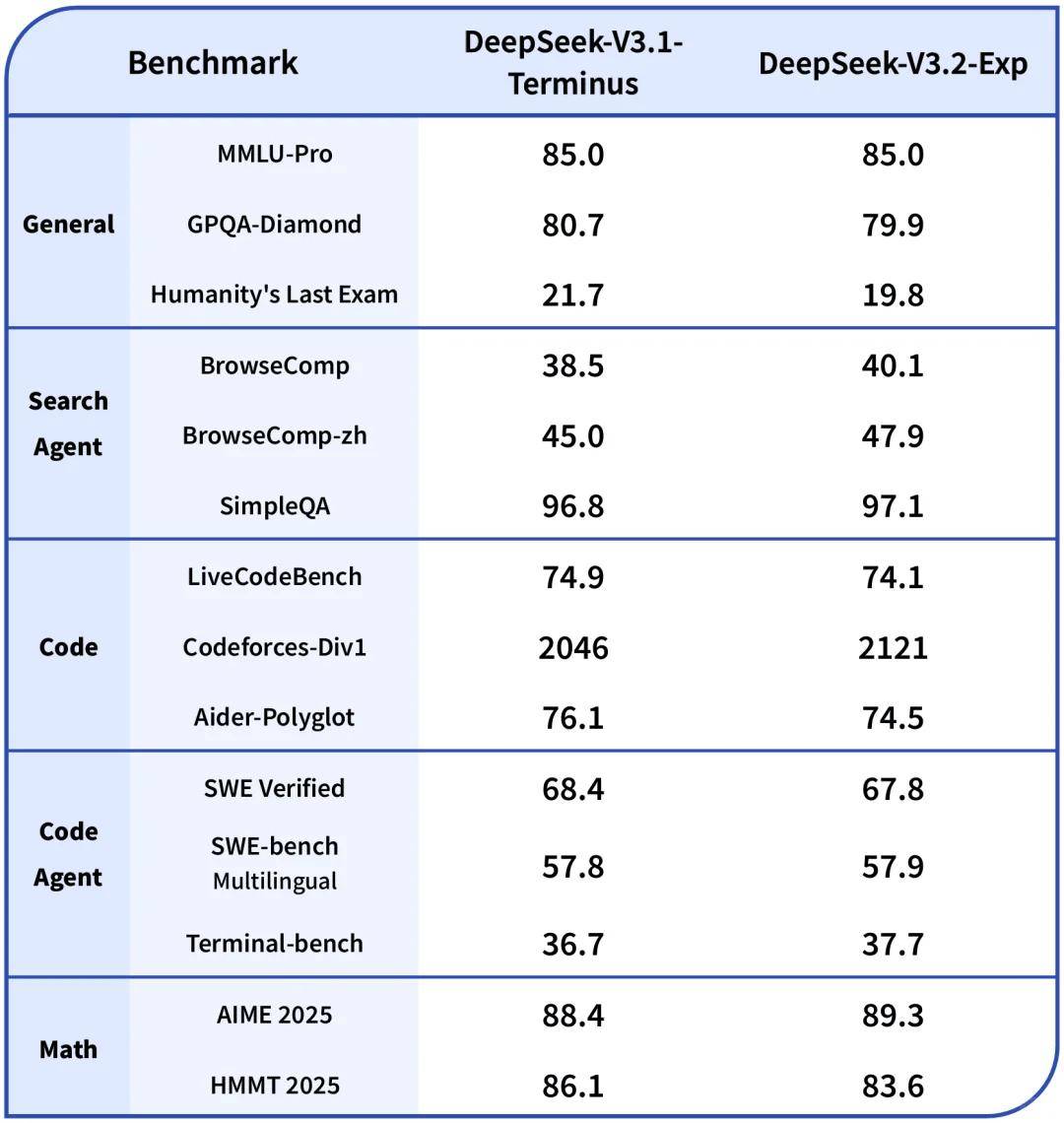
更值得关注的是生态进展。华为云已完成对该模型的全面适配,采用大EP并行方案支持160K长序列处理。“这相当于让模型‘一口气读完《战争与和平》并精准回答细节问题’。”华为云AI负责人在接受采访时表示,双方联合优化的推理引擎,可将长文本处理延迟控制在500ms以内,满足企业级实时交互需求。
开发者社区反应热烈。某电商技术负责人透露:“之前用同类模型处理用户行为日志,单次调用成本约12元,现在用V3.2-Exp能压缩到5元以内,年节省近百万。”官方同步提供V3.1-Terminus接口供对比测试,截至发稿,Hugging Face开源页面星标数已突破1.2万,GitHub代码库fork量超3000次。
557万美元训练成本 挑战算力军备竞赛
“用557万美元实现与GPT-4o相当的性能”——这一标签自DeepSeek-V3系列发布以来便引发行业震动。此次V3.2-Exp进一步验证了“高效训练”路线的可行性:通过算法优化而非堆砌算力,将大模型研发从“百亿美金游戏”拉回“千万美元级别”。
外媒The Verge将其称为“东方的神秘力量”,OpenAI前员工Andrej Karpathy在X平台评价:“他们证明了智能增长未必依赖算力指数级提升,稀疏化架构可能是下一个突破口。”这种技术路径正倒逼行业反思:当参数规模触及物理极限,效率优化会成为新的竞争焦点吗?
不过,实验性版本的定位也意味着挑战。官方强调,尽管公开评测表现稳定,但真实场景下的大规模验证仍需时间。“我们保留V3.1接口,就是希望开发者帮助我们发现极端场景下的问题。”DeepSeek产品负责人表示,未来三个月将根据反馈迭代,目标是2026年Q1推出正式版。
从“算力至上”到“效率为王”,DeepSeek的这次“实验”或许正在撕开一道口子。当稀疏注意力、低成本训练、开源生态形成合力,AI行业的“军备竞赛”会转向“效率竞赛”吗?至少现在,答案已经写在了API降价50%的公告里。
本文来自投稿,不代表火星财经立场,如若转载,请注明出处:https://www.sengcheng.com/article/101808.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 