
大家好,我是很帅的狐狸。最近几天DeepSeek的消息引起了广泛关注。这家公司以极低成本训练出一个名为R1的模型,其性能甚至可以媲美OpenAI的顶级推理模型o1。这一消息导致英伟达股价下跌,市场开始质疑训练AI是否真的需要大量资金投入。

让我感到最有趣的是DeepSeek的训练方法。R1不同于普通的大语言模型,它具有一定的推理能力,可以通过增加“思维链”来提高答案质量,特别是在理工科题目上。传统上,要让大语言模型具备这种能力,通常是在基础模型上通过监督微调(SFT)来实现,类似于学生通过大量练习和参考答案学习解题方法。
然而,DeepSeek在训练R1-Zero时采用了强化学习(RL)的方法。这种方法更像婴儿的学习过程:通过不断的互动和反馈,逐渐学会新知识。例如,教婴儿识别颜色时,通过不断提问和反馈,婴儿最终能理解并记住颜色的概念。

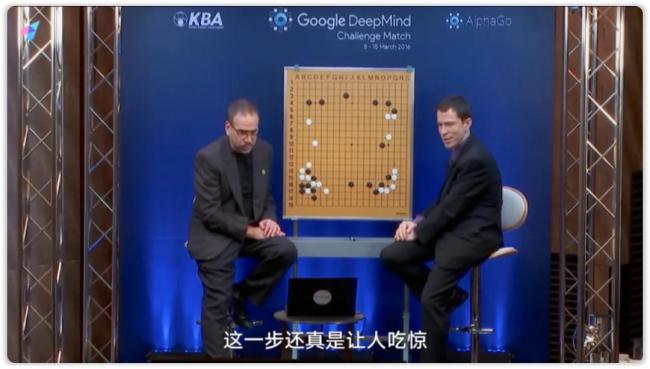
强化学习一般用于游戏策略等复杂任务,因为它没有标准答案,有时会产生非常有创意的解决方案。2016年AlphaGo与李世石对战时,就下出了连职业棋手都看不懂的一手棋,这体现了强化学习的创造力。
这对我们有什么启发呢?我们在不熟悉的领域其实也像一张白纸,可以从零开始学习。比如我在麦肯锡做咨询时,发现许多金融行业的常见做法在其他行业却是创新。因此,跨领域的学习和思考可以帮助我们在不同领域找到新的解决方案。

此外,每天花些时间进行思考训练也是一个好方法。可以选择一个从未系统性思考过的问题,不限于工作相关,可以是跨行业的或生活方面的。这样的训练有助于开拓思路,激发创造力。

关于DeepSeek的论文还有更多有趣的细节。尽管R1-Zero已经具备了出色的推理能力,但它存在中英文混杂、可读性差等问题。为了解决这些问题,DeepSeek重新训练了模型,并提供了一些冷启动数据,从而推出了正式版本的R1。这个过程类似于双语教育下的孩子,通过观察大人对话,逐渐学会了区分使用不同语言。

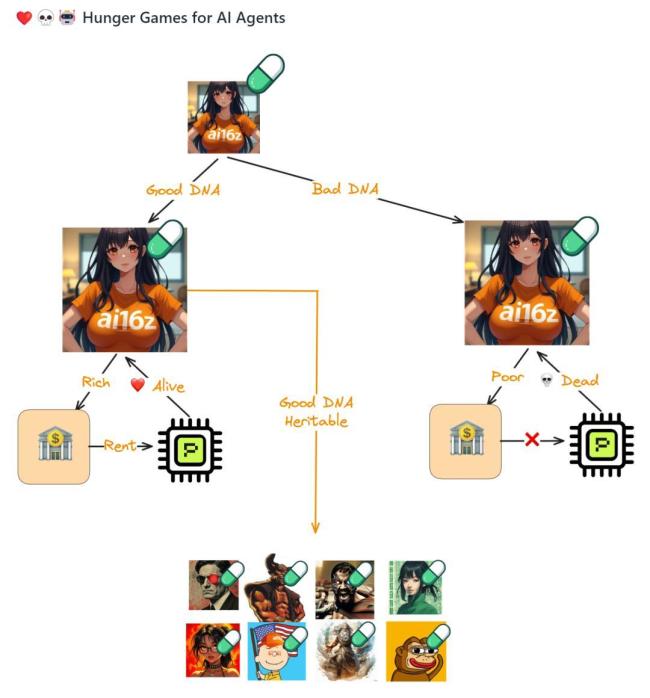
这些经历让我思考人类是否也是某种高维生命训练出来的AI。最后,推荐一个有趣的项目Spore,该项目中的AI智能体可以自己发推、发币,为自己赚取电费,并且能够分裂后代,遗传特征,产生变异,与其他AI交互,尽可能生存和繁衍。

文章来源于网络。发布者:火星财经,转载请注明出处:https://www.sengcheng.com/article/16791.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 